

精准编辑的“导航仪”:PRIDICT2.0与ePRIDICT如何系统性优化prime editing实验设计
Prime editing(先导编辑)作为新一代无双链断裂的精准基因编辑技术,近年来迅速成为基础研究与基因治疗开发的核心工具。然而,其效率高度依赖于pegRNA(prime editing guide RNA)的设计与靶位点的染色质环境——变量繁多、试错成本高昂,极大限制了技术的规模化应用。2025年,苏黎世大学Schwank团队在Nature Biotechnology与Nature Protocols连续发表升级版计算工具 PRIDICT2.0 与 ePRIDICT,首次实现了从序列层面到表观层面的编辑效率联合预测,为prime editing提供了系统性设计框架。

一、为何需要PRIDICT2.0?——破解pegRNA设计的“组合爆炸”难题
一个目标位点上,可设计的pegRNA数量常达数千:protospacer序列、PBS(primer binding site)长度(通常10–15 nt)、RTT(reverse transcription template)长度(含编辑序列与同源臂),以及编辑类型(替换、插入、缺失)均可自由组合。传统经验规则(如PBS=13 nt、RTT overhang=10 nt)仅适用于部分场景,且对>3 bp编辑预测能力有限。
PRIDICT2.0的突破在于:
基于大规模实验数据训练:整合HEK293T(MMR缺陷)与K562(MMR完整)细胞中近10万条pegRNA的高通量筛选数据;
支持复杂编辑类型:可预测最长40 bp的插入/缺失/替换,并首次支持“沉默旁观者编辑”(silent bystander edits)——即在不改变氨基酸序列前提下引入同义突变,以规避错配修复(MMR)通路抑制,显著提升短编辑效率;
双模型适配不同细胞背景:提供MMR−(HEK293T模型)与MMR+(K562模型)两套评分体系,指导用户根据靶细胞修复状态选择最优设计。
实测显示(Nat. Biotechnol. 2025),在100个ClinVar致病点突变的模拟设计中,PRIDICT2.0精选的pegRNA中位预测分显著优于随机筛选或传统规则设计;若进一步引入沉默编辑,K562模型下效率预测值提升超30%。
二、为何还需ePRIDICT?——染色质环境是编辑效率的“隐形开关”
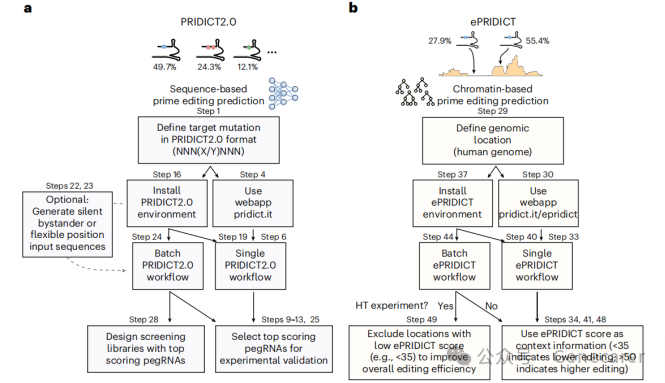
即使pegRNA设计完美,若靶位点位于异染色质区域(如H3K9me3/H3K27me3富集区),编辑效率仍可能极低。Schwank团队创新性采用TRIP技术(Thousands of Reporters Integrated in Parallel),将同一报告系统整合至基因组数千不同位点,排除序列干扰,首次系统量化染色质状态对prime editing的影响。
结果明确显示:
开放染色质(如启动子、基因体)显著促进编辑;
封闭/抑制性染色质 导致效率大幅下降。
基于此,团队开发了ePRIDICT——一个基于XGBoost的梯度提升模型,整合ENCODE中6项(light版)或455项(full版)K562表观组学数据(DNase-seq、H3K4me1/2、HDAC2等),对任意hg38坐标输出0–100的“染色质友好度”评分:
>50:高概率高效编辑;
<35:建议规避或预处理(如CRISPRa激活);
支持全基因组批量扫描,助力高通量文库设计。
值得注意的是,当前ePRIDICT仅适用于人类基因组,且基于K562细胞训练;作者验证其在HEK293T、HepG2中仍具较好泛化性,但对染色质差异显著的细胞系(如神经元、原代T细胞),建议辅以本地ChIP-seq数据校验。
三、如何使用?——兼顾便捷性与可扩展性
两项工具均提供网页版与本地部署双路径:
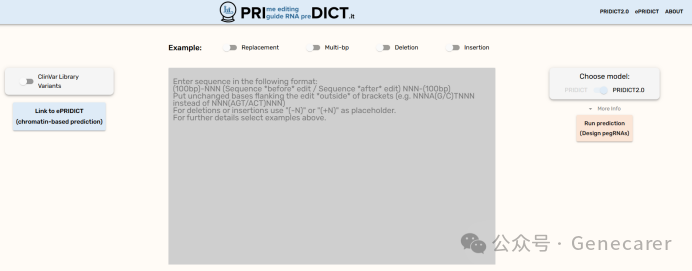
网页端(www.pridict.it / epridict.it ):
无需编程基础,输入编辑序列(如(...A/G...))或基因组坐标(chrX:123456),1分钟内返回排序pegRNA列表(含spacer/PBS/RTT序列、nicking guide推荐、NGS引物设计)及ePRIDICT评分——适合单靶点快速筛选。
本地部署(GitHub开源):
基于Conda+Python环境,支持:
批量预测数百至数千编辑(HPC集群并行加速);
自动生成沉默编辑变体;
灵活定位插入/缺失(如“在50 bp窗口内寻找最优终止密码子位点”);
与自动化克隆流程(如Addgene #174038载体)无缝衔接。
四、未来方向与注意事项
尽管PRIDICT2.0/ePRIDICT大幅提升设计成功率,仍需注意以下几点:
不支持>40 bp编辑或混合编辑类型(如插入+替换);
未建模PE3/PE5中的nicking guide协同效应(仅额外提供DeepSpCas9评分供参考);
对非NGG PAM靶点需结合DeepPrime等工具;
U6启动子表达的pegRNA中poly(T)序列影响已纳入模型,但合成pegRNA可能不受此限,需谨慎解读。
展望未来,结合细胞类型特异性表观图谱(如原代细胞ATAC-seq)的定制化ePRIDICT模型,以及整合脱靶预测(如DeepPrime-Off)的全流程平台,将是下一阶段重点。
结语:
从“盲筛”走向“精算”,PRIDICT2.0与ePRIDICT标志着prime editing正式迈入可预测、可编程、可规模化的新阶段。对于正在开展基因功能研究、疾病建模或基因治疗开发的团队,它们不仅是效率倍增器,更是实验设计逻辑的一次范式升级——让每一次编辑,都始于深思熟虑的计算,而非侥幸的尝试。
工具链接
官网:PRIDICT.it - pegRNA Prediction
PRIDICT2.0代码:https://github.com/uzh-dqbm-cmi/PRIDICT2
ePRIDICT代码:https://github.com/Schwank-Lab/epridict
原文:Nat. Protoc. (2025) https://doi.org/10.1038/s41596-025-01244-7
我司可提供Primer Editor pegRNA 载体构建、PE3载体构建(一套)、TwinPE 载体构建、以及Lenti-PE-gRNA慢病毒包装、PE3b-腺病毒包装、Twin-PE-腺病毒包装、点突变细胞珠的构建
